
GPT-4.1
OpenAI 最新智慧模型 GPT-4.1:具有卓越的程式設計能力、百萬符號處理能力和精確的指令執行。
GPT-4.1:重新定義先進的 AI 能力
編碼能力突破,效率提升
GPT 4.1 在 SWE-bench 測試中達到 54.6% 的完成率,遠超 GPT-4o 的 33.2%。它在探索程式碼庫和生成可運行並通過測試的程式碼方面表現出色。
實際改進包括 3 倍更好的程式碼差異可靠性和增強的前端開發(80% 評審者偏好)。冗餘編輯從 9% 降至 2%。
在功能開發、除錯或程式碼審查中,GPT-4.1 提供精確、高效的支援,成為開發者的必備工具。
實際改進包括 3 倍更好的程式碼差異可靠性和增強的前端開發(80% 評審者偏好)。冗餘編輯從 9% 降至 2%。
在功能開發、除錯或程式碼審查中,GPT-4.1 提供精確、高效的支援,成為開發者的必備工具。
增強的指令遵循,更自然的對話
GPT 4.1 精通指令理解與執行,能準確處理格式要求、負面指令和內容標準,提升了精確度。
在多輪對話中,GPT 4.1 比 GPT-4o 提高了 10.5%,更好地利用對話歷史,實現更連貫的溝通。
在稅務分析中,GPT 4.1 顯示出 53% 的準確度提升,突顯其在專業法規和複雜指令上的優勢。這些進步增強了 AI 在企業支持、專業分析和日常互動中的可靠性。
在多輪對話中,GPT 4.1 比 GPT-4o 提高了 10.5%,更好地利用對話歷史,實現更連貫的溝通。
在稅務分析中,GPT 4.1 顯示出 53% 的準確度提升,突顯其在專業法規和複雜指令上的優勢。這些進步增強了 AI 在企業支持、專業分析和日常互動中的可靠性。
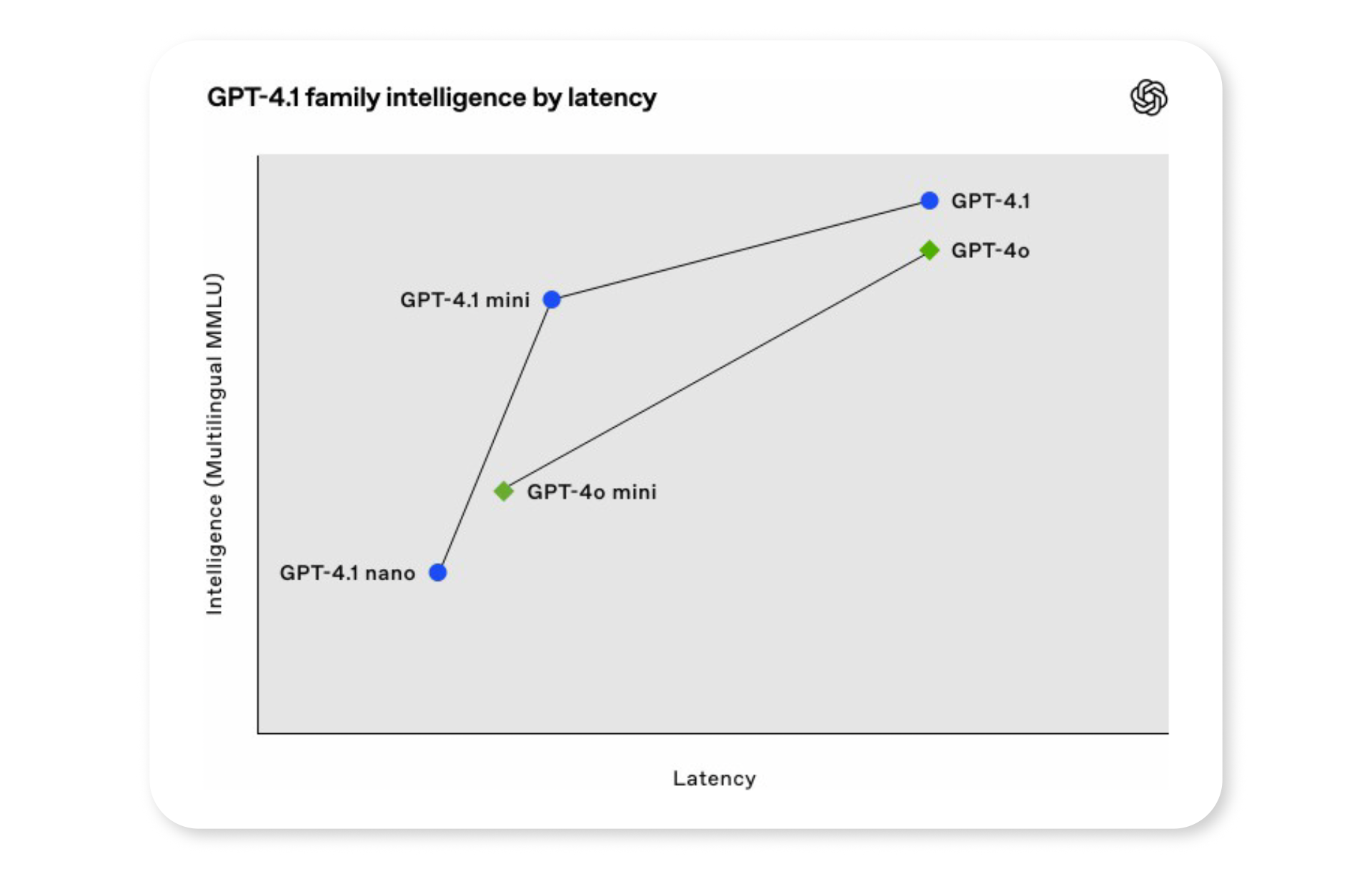
超長上下文理解能力
GPT 4.1 支持 100 萬標記(約 750,000 字),超越《戰爭與和平》全文。這允許在保持連貫性的同時處理大量文件和代碼庫。
這項能力使得 GPT 4.1 成為研究與法律分析的理想選擇,使開發者能夠創建具更強記憶能力的智能應用程式。
這項能力使得 GPT 4.1 成為研究與法律分析的理想選擇,使開發者能夠創建具更強記憶能力的智能應用程式。
卓越的影像理解,輕鬆處理影片內容
GPT 4.1 的視覺能力能準確解釋圖像、圖表和影片內容。擅長科學圖表解釋和視覺數學問題。
特別出色的是,它能在沒有字幕的情況下理解30-60分鐘的影片,並準確回答內容問題。這創造了一個全能的多媒體助手,簡化了視覺內容處理。
👉 現在下載插件,體驗全面的影片和圖像理解能力。
特別出色的是,它能在沒有字幕的情況下理解30-60分鐘的影片,並準確回答內容問題。這創造了一個全能的多媒體助手,簡化了視覺內容處理。
👉 現在下載插件,體驗全面的影片和圖像理解能力。

了解 GPT-4.1 模型系列
OpenAI 的 GPT 4.1 系列模型,包括 GPT 4.1 Mini 和 GPT 4.1 Nano,提供適合快速回應和低成本運行應用程序的高效經濟解決方案。
比較 GPT-4.1 與其他模型
深入分析 GPT-4.1、GPT-4.5 和 Claude 3.7 Sonnet 之間的特性和性能差異,揭示它們在程式碼建議和其他應用領域的表現。
GPT-4.1 VS GPT-4.5
GPT-4.1 VS Claude 3.7 Sonnet
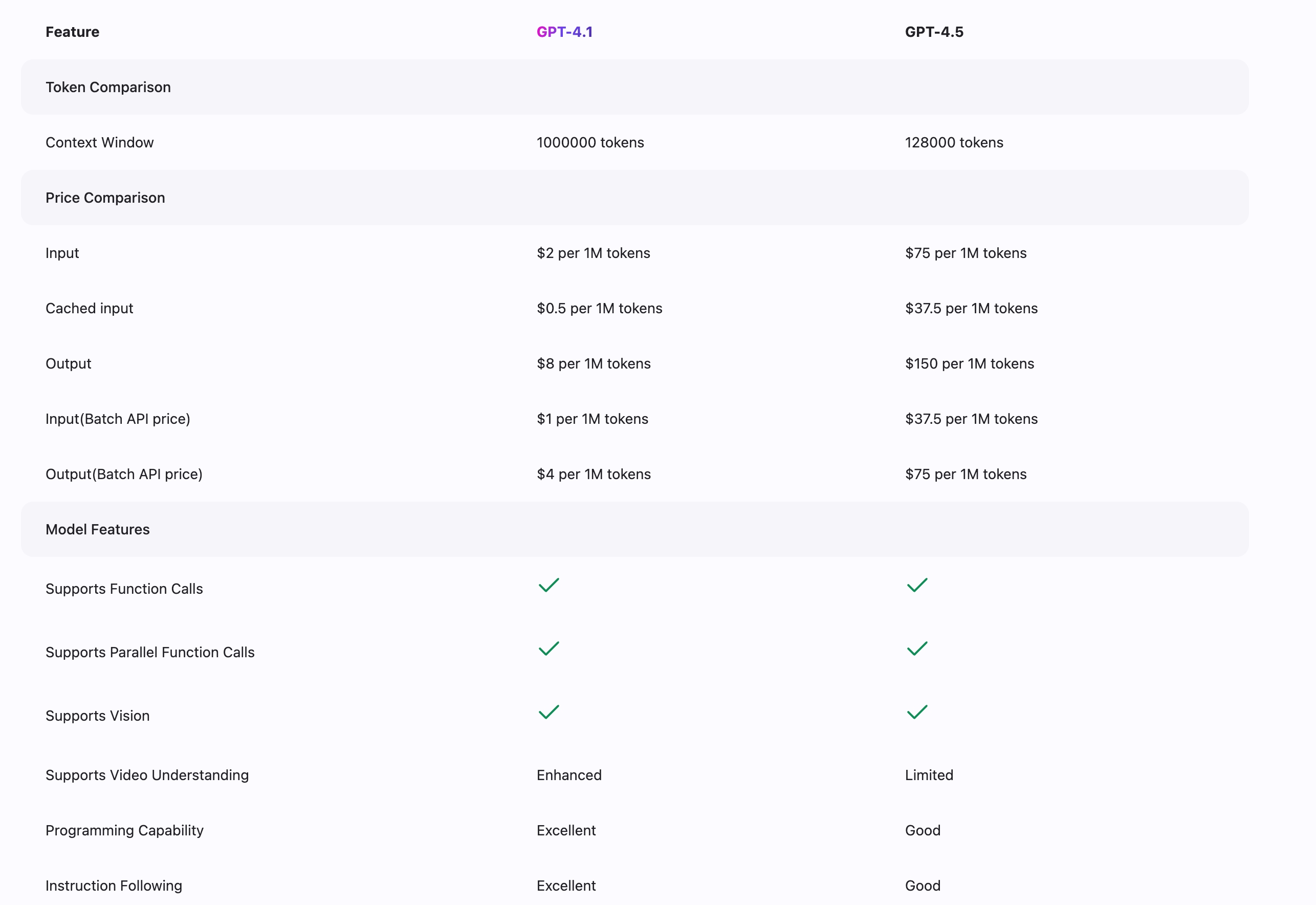
探索 GPT-4.1 和 GPT-4.5 模型之間的關鍵特性、能力和差異。
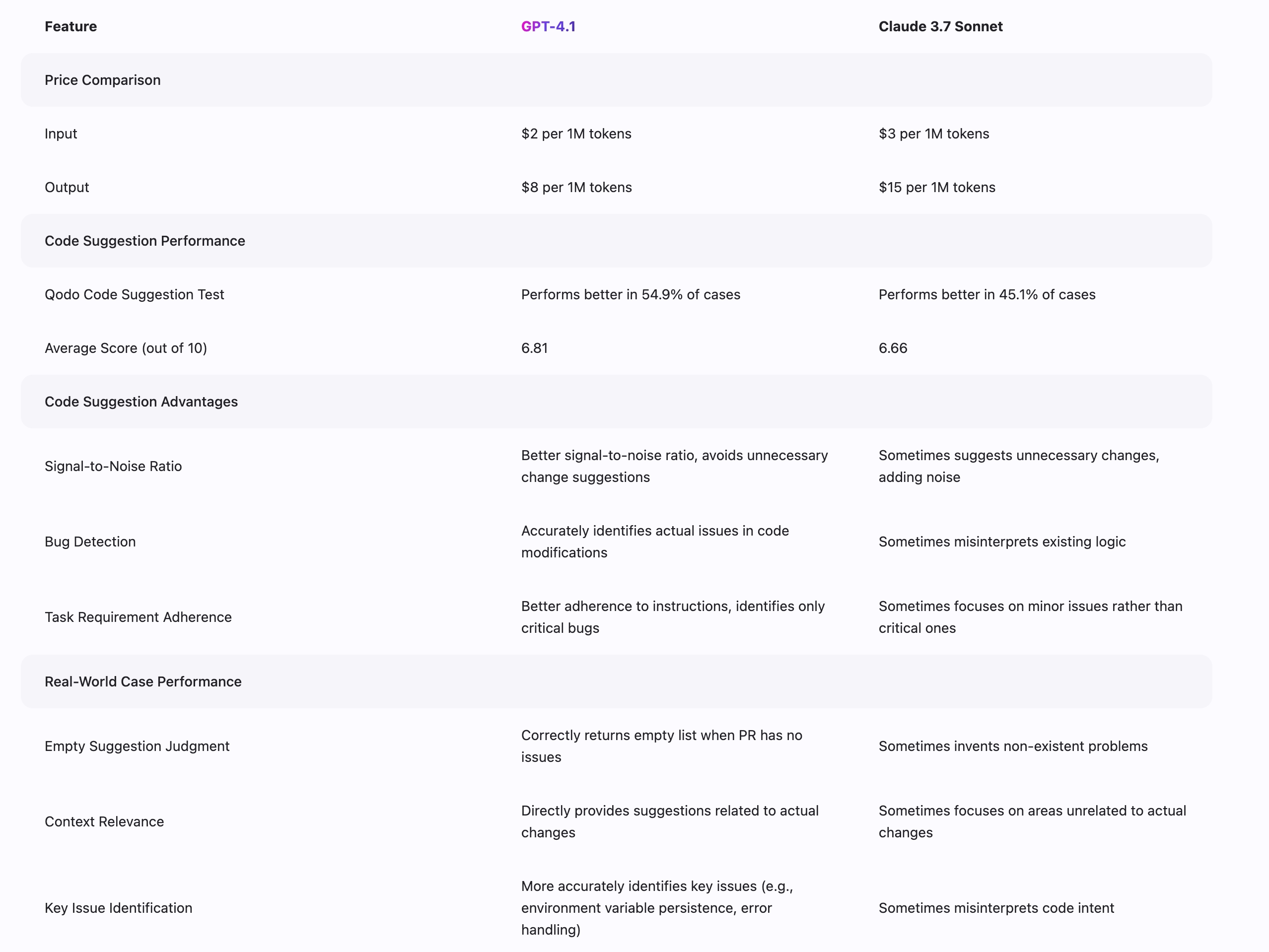
根據 Qodo.ai 的基準數據比較兩個模型在程式碼建議中的性能
常見問題解答
GPT 4.1 是何時發布的?
GPT-4.1 於 2025 年 4 月發布,在編碼、指令遵循和視覺理解能力上有顯著提升。
GPT-4.1 的基準測試結果如何?
GPT 4.1 的基準測試顯示在多個指標上取得了顯著的提升,包括在 SWE-bench 測試中達到 54.6% 的完成率(相比之下 GPT-4o 為 33.2%),在對話連貫性上提升了 10.5%,以及在複雜稅務分析上提高了 53% 的準確性。
如何訪問 GPT-4.1 的 API?
可以通過 OpenAI 的開發者平台 獲得 GPT 4.1 API。您需要註冊 API 訪問權限,並使用提供的文檔和 SDK 進行整合。
GPT-4.1 是否可在 Azure 上使用?
是的,GPT 4.1 Azure 完全整合到 Azure OpenAI 服務中。
GPT 4.1 的成本結構是什麼?
GPT-4.1 系列提供基於輸入和輸出標記的分級定價結構:GPT-4.1 標準版的輸入費用為每百萬標記 $2.00(緩存輸入為每百萬標記 $0.50),輸出費用為每百萬標記 $8.00。GPT-4.1 Mini 更具經濟性,輸入費用為每百萬標記 $0.40,輸出費用為每百萬標記 $1.60。最具成本效益的選擇是 GPT-4.1 Nano,輸入費用僅為每百萬標記 $0.10,輸出費用為每百萬標記 $0.40。
是否有 GPT 4.1 mini 版本可用?
是的,GPT-4.1 mini 提供該模型的更小版本,參數減少,為不太苛刻的應用提供性能和成本之間的平衡。它在日常任務中表現出色,同時比完整版本更經濟。您可以立即在 Monica AI 上試用 GPT-4.1 mini,親身體驗其功能,看看它如何提高您的生產力,同時保持預算效率。
GPT 4.1 mini 的定價與完整版相比如何?
GPT-4.1 mini 的價格比完整版低 80%,輸入成本為每百萬標記 $0.40(對比 $2.00),輸出成本為每百萬標記 $1.60(對比 $8.00)。這使其成為小型企業和預算受限專案的理想選擇,同時保持優異的性能。
GPT 4.1 與 4.5 的比較如何?
GPT-4.1 提供了 100 萬標記的上下文窗口(相比之下,GPT-4.5 為 128,000 標記),在 SWE-bench 測試中達到了 54.6% 的完成率。GPT-4.1 在視覺理解和多輪對話任務中表現優異,在編程和遵循指令方面有顯著優勢。此外,GPT-4.1 比 GPT-4.5 更具成本效益,讓先進的 AI 能力更廣泛地被使用。雖然 GPT-4.5 可能在某些特定推理任務中更具優勢,但 GPT-4.1 為大部分應用提供了一個優秀的能力、性能和價值平衡。
GPT 4.1 與 Claude 3.7 的差異是什麼?
GPT-4.1 與 Claude 3.7 代表了不同的高級 AI 方法。GPT-4.1 在程式碼生成上(SWE-bench 的完成率為 54.6%,而 Claude 3.7 為 48.3%)以及視覺理解任務中表現出色,具備處理複雜影像和視頻內容的優勢。它還提供了 100 萬標記的更長上下文窗口。Claude 3.7 在細緻推理、事實準確性和某些專業知識領域展現優勢。GPT-4.1 一般在程式設計任務、多模態應用和技術內容生成上更有效率,而 Claude 3.7 在需要謹慎推理和精確指令遵循的任務中可能表現更好。價錢也不同,GPT-4.1 通常為同等能力提供更具競爭力的價格。
GPT-4.1 在 Reddit 上的評價如何?
GPT 4.1 在 Reddit 社群中的反饋非常正面,使用者特別欣賞其強大的程式能力與長上下文處理。GPT-4.1 在 Reddit 討論中的熱門話題包括與 Claude 3.7 的比較、性價比以及 Mini 版本的實用性。整體而言,GPT-4.1 因其程式碼生成品質以及處理大型專案的能力而受到技術社群的高度推崇。